There have been some changes. A minor re-organisation that brings the Office of the CTO closer to the delivery end of the business – with a renewed focus on innovation and technology leadership. This makes me much happier.
I brokered a successful introduction between a data science contact I made at the recent AWS event and my OCTO colleague who looks after data and analytics.
I did some script-writing as preparation for some podcasts we’re recording next week.
And I published a blog post about the supposed demise of cloud, where apparently lots of people are moving back on-premises because it’s “too expensive”. Hmmm:
Also, because nobody engages with AI blog posts, I made a little observation on LinkedIn:
I spent quite a bit of time working on the ransomware offering that I’ve mentioned a few times now. Once we finalise the cost model I’ll start to shout some more.
And someone actually booked some time with me using my Microsoft Bookings page!
Matt is happy in Spain (for a few weeks), riding his bike in the sunshine and mixing with professionals and amateurs alike.
Two new cyclocross frames arrived last week too, so his bedroom back home looks like a workshop as he prepares for gravel/cyclocross later in the year.
Unfortunately, his groupset is wearing out (the interior components on Shimano 105-spec shifters are fine for leisure riders like me, but not for people who ride more miles on their bike than many people drive). Alpkit were selling off some surplus 105 Di2 groupsets and one is now in our house. The theory being that there’s less to wear out with an electronic groupset. I’m not convinced!
Ben had a great half term holiday with friends in Devon. He’s back home safely now. The Young Person’s Railcard is a wonderful scheme.
And I’m bouncing from day to day, ticking things off lists and generally trying to balance being a good Dad, a good husband, and to get myself back in shape, mentally and physically. Once I’d finished work for the week:
I took myself along to a talk about using multimeters, at one of the local clubs and societies in Olney, which filled a few gaps in my geek knowledge before I caught up with my friend James for a couple of pints.
And I took a ride on a local railway line that’s recently reopened after a year or so with no service. For a few weeks it’s £1 each way between Bedford and Bletchley so I decided to get a different view of the various developments along the Marston Vale. Old brickworks are now energy recovery facilities and country parks, but there’s lots more to see too.
In tech
OpenAI launched a text-to-video model called Sora:
Amazing, yet incredibly scary. We don’t yet have the social constructs to manage how we use (and guard against misuse of) AI. Detecting fake from real images is already hard. It just got significantly more difficult… https://t.co/VigmM3MILV
Whilst I feel for Kate (@katebevan), I’m pleased to see someone else finds these UI features as frustrating as me. See also country dropdowns where I scroll and scroll to get to United Kingdom but someone thought the USA was important enough to put at the top of the list:
Filling in your date of birth is LITERAL VIOLENCE when you're as old as I am and have to scroll back through untold numbers of decades to reach the year you were born pic.twitter.com/EHMA3atAC7
I’ve seen a few articles recently that talking about how organisations are moving workloads out of the cloud and back to their own datacentres. Sometimes they are little more than clickbait. But there is a really important discussion to be had here. So I thought I’d lift the lid on this topic and have a look at what I think is really going on.
The promise of the cloud
Cloud is great for many things. On-demand access to vast amounts of computing and storage resource, on a pay as you go basis. Brilliant. No need to invest in capital. Just pay for what you use.
Except that’s not how all businesses work. At least not for all application workloads and data sets.
Possibly the most famous of these “we found cloud expensive and moved back on-prem” articles is David Heinemeier Hansson (@DHH)’s why we’re leaving the cloud post for 37 Signals, written in 2022. In that post, DHH says that renting someone else’s computers didn’t work for his business. He describes 37 Signals as a “medium-sized business with stable growth”. But, I’m willing to bet that most of the readers of this post are not running SaaS applications in AWS for a global audience of B2B and B2C customers. Some will be, but most of my clients are not.
In fact, in his video on kicking cloud to the curb [sic], David Linthicum (@DavidLinthicum) flags that SaaS providers will scale in a repeated pattern, whereas enterprise [and SME] workloads scale differently. Cloud still has a place for most organisations. DHH’s follow-up post (the Big Cloud Exit FAQ) is worth a read too. Just remember that most business don’t follow the profile of 37 Signals. And that 37 Signals are still using co-lo facilities (because building new datacentres in 2024 is a very brave move, unless you are a hyperscaler).
But you’re not 37 Signals
In 2024, I would seriously question why anyone is running their own office productivity tools (email, IM, intranet, etc.) on-premises. There are many services that can do this for you on a per-person-per-month basis. And they will have better up-time than you ever did, despite what your former email administrator tells you. Those jokes about “Microsoft 364” whenever there’s a blip in the matrix… how much more did you spend on storage to make sure that you got to even 99.5% availability in your Exchange servers?
But let’s move on past the “low hanging fruit” that can relatively easily be replaced by SaaS. Let’s have a look at all those other applications that actually run your business: the finance system; the case management system; the modern data platform; the reporting and analytics; the years and years of accumulated unstructured file data that no-one knows what is needed and what is not. (“The business”* says “that it’s up to IT to sort out”. IT says “we don’t know what you need”. No-one agrees to the blanket retention policies, just in case that file deleted after 3, 7, 10 years is really important.)
What I’ve seen happen, time and time again, is that almost everything is moved to the cloud. I say almost, because the cloud discovery process often turns up evidence of virtual machines that were created, are no longer used, but are left running. This happens because on-premises infrastructure is seen as “paid for”. There is no cost to leaving things running. Except there is – not just in wasted processor cycles and storage, but in the size of the infrastructure that’s required.
Lifting and shifting without transformation
There are many motivations for cloud migrations but the most common I see is because the datacentre is closing. Maybe it’s the end of an outsource, maybe the site is being sold for redevelopment. But it’s nearly always “we must exit by” a particular date. No time to transform – just transition. We’ll sort it out later. Except “later” never comes. The project to move to the cloud is completed. The team is stood down. The partners are disengaged. “Phase 2” to transform the estate doesn’t have a strong enough business case** and things stay the same.
And then the cloud bills come in. They look a bit steep – especially for IaaS. You’re using more storage than you expected, and those VMs are a little pricey. Some “optimisation” is done to adjust VM sizes. Reserved Instances and other benefits are used to reduce the monthly charge.
Watch the costs rise
A year later, the prices rise. Inflation. Exchange rate variance vs. the $ or the € (depending on your provider’s base currency). That’s OK, it was always expected. Wasn’t it? Another round of “optimisation” happens. A couple of applications are no longer used, replaced by SaaS. Some VMs are switched off.
Rinse and repeat. Rinse and repeat.
A few years on, but you’ve still not transformed. Those resources that you “lifted and shifted” to the cloud are, like the old adage, the same computers running in someone else’s data centre.
The CFO looks at the cloud bill and says “how much?!”. It looks astronomical compared with industry norms. They bring in a new Head of IT and tell them that they have to reduce the cloud spend. “We’ll move back on-premises – where it used to cost less”, they agree.
But it’s still the same systems. With the same technical debt. And now it needs power, and water, and expensive servers and storage and… you see where we are going.
Refactor or modernise
Cloud is not a cycle, like in-source/out-source. It’s a business model. And, like all business models you need to tune the way they are used to make best use of them. N-tier applications running on VMs in IaaS will generally not be cost-effective. Look at how to move the presentation tier to web services. Can the application be re-factored? Could the database run in PaaS too? Often the challenge is ISV support. But it’s 2024. If your vendor doesn’t have native support for Azure or AWS, maybe it’s time to find a different vendor.
And if you’re moving to the cloud to save money, maybe it’s time to look again at your business case.
Use the cloud for innovation, not to save money
Cloud can save money. But only after the workloads are transformed. And only then with continual optimisation. The trick is to make the effort you put into transformation cost less than the savings you return through efficiencies. We can do this on-prem too, but it normally involves capital spend. And that’s another major advantage of the cloud. Once you’re there you can use it to try out new products and services, without a major investment. All that AI innovation that’s happening right now. You can try it out in the cloud, for relatively little effort. Now imagine you needed an investment case for the infrastructure to develop new AI models in house? Cloud gave you agility and flexibility.
And don’t forget about efficiency
To borrow a metaphor from David Linthicum, remember that cloud is a utility. If you leave the heating and lights on at home, you can expect a big bill. It’s no different in the cloud, if you run inefficient infrastructure and applications.
Look at the long-term viability and placement for your services, Make right-sizing decisions based on application workload and datasets. The problem isn’t the cloud – it’s that some people are trying to use it for the wrong things.
* I used this term to be deliberately provocative. I could write a whole separate post on the concept of “the business” vs. “IT”. ** It should have. If properly thought through.
This content is 3 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
This week I’ve been struggling to focus but still moved a few things forwards. I also kept bumping up against some bizarre (non) efforts at “digital transformation”, courtesy of Standard Life (abrdn), Costco and the UK Government.
This week’s highlights included:
Adapting David Clark and Sophie Marshall’s “Simple Stack” diagram for the purposes of my team at risual. I hope to republish soon in blog format as it’s licenced under Creative Commons.
Changing my display name to remove all the vowels because apparently that’s how digital transformation is done these days:
Oh god please hire some people who understand that digital is just how most people live their lives now and not removal of vowels https://t.co/rnoTDWYA4u
Joining the Environmental Sustainability group at risual.
Despairing over school communications:
Only a school could communicate like this: message sent to parents' email (using @IRISParentMail) with a .DOCX (Microsoft Word) attachment which, assuming you have the necessary software to read it, is a letter informing that the school will be posting an FAQ on its website ????
Visiting a shopping centre! I picked my moment: 18:30 on a Friday is a) quiet and b) free parking in Central Milton Keynes. I was quickly in and out of Next and John Lewis with minimal human contact…
Realising that digital transformation hasn’t reached Costco UK yet – and no membership card means no entry and no shopping:
Almost all transactions I make these days use a digital wallet (one exception is the local market). Unfortunately, I just went to @CostcoUK and only had my phone with me ????. No membership card ? and no ID to get a replacement card means no shopping ?? #DigitalTransformation
Looking ahead to the (long) weekend, I have no races to take the eldest teenager to and the weather ins’t looking wonderful. So, just the usual Youth Cycle Coaching on Saturday and, hopefully, some relaxing and pottering at “geek stuff” in the Man Cave…
This week in photos
No Insta’ from me yet this week (maybe there will be over the long weekend) so here’s a Line of Duty meme instead:
This content is 4 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
A few years ago, a couple of colleagues showed me something they had been working on – a “5 Rs” approach to classifying applications for cloud transformation. It was adopted for use in client engagements but I decided it needed to be extended – there was no “do nothing” option, so I added “Remain” as a 6th R.
I later discovered that my colleagues were not the first to come up with this model. When challenged, they maintained that it was an original idea (and I was convinced someone had stolen our IP when I saw it used by another IT services organisation!). Research suggests Gartner defined 5Rs in 2010 and both Microsoft and Amazon Web Services have since created their own variations (5Rs in the Microsoft Cloud Adoption Framework and 6Rs in Amazon Web Services’ Application Migration Strategies). I’m sure there are other variations too, but these are the main ones I come across.
For reference, this is the description of the 6Rs that we use where I work, at risual:
Replace (or repurchase) – with an equivalent software as a service (SaaS) application.
Rehost – move to IaaS (lift and shift). This is relatively fast, with minimal modification but won’t take advantage of cloud characteristics like auto-scaling.
Refactor (or replatform/revise) – decouple and move to PaaS. This may provide lower hosting and operational costs together with auto-scaling and high availability by default.
Redesign (or rebuild/rearchitect) – redevelop into a cloud-aware solution. For example, if a legacy application is providing good value but cannot be easily migrated, the application may be modernised by rebuilding it in the cloud. This is the most complicated approach and will involve creating a new architecture to add business value to the core application through the incorporation of additional cloud services.
Remain (or retain/revisit) – for those cases where the “do nothing” approach is appropriate although, even then, there may be optimisations that can be made to the way that the application service is provided.
Retire – for applications that have reached the end of their lifecycle and are no longer required.
Right now, I’m doing some work with a client who is looking at how to transform their IT estate and the 5/6Rs have come into play. To help my client, who is also working with both Microsoft and AWS, I needed to compare our version with Gartner’s, Microsoft’s and AWS’… and this is what I came up with:
risual
Gartner
Microsoft
AWS
Notes
Replace
Replace
Replace
Repurchase
Whilst AWS uses a different term, the approach is broadly similar – look to replace/repurchase existing solutions with a SaaS alternative: e.g. Office 365, Dynamics 365, Salesforce, WorkDay, etc.
Rehost
Rehost
Rehost
Rehost
All are closely aligned in thinking – rehost is the “lift and shift” option – based on infrastructure as a service (IaaS) – which is generally straightforward from a technical perspective but may not deliver the same long term benefits as other cloud transformation methods.
Refactor
Refactor
Refactor
Replatform
Refactoring generally involves the adoption of PaaS – for example making use of particular cloud frameworks, application hosting or database services; however this may be at the expense of portability between clouds. The exception is AWS, which uses refactor in a slightly different context and replatform for what is referred to as “lift, tinker and shift”.
Revise
Gartner’s revise relates to modifying existing code before refactoring or rehosting. risual, Microsoft and AWS would all consider this as part of the refactoring/replatforming.
Redesign
Rebuild
Rebuild
Refactor/re-architect.
Gartner defines rebuilding as moving to PaaS, rebuilding the solution and rearchitecting the application.
AWS groups its definition of refactoring and rearchitecting, although the definition of refactor is closer to Microsoft/Gartner’s rebuild – adding features, scale, or performance that would otherwise be difficult to achieve in the application’s existing environment (for example.
Rearchitect
Microsoft makes the distinction between rebuilding (creating a new cloud-native codebase) and rearchitecting (looking for cost and operational efficiencies in applications that are cloud-capable but not cloud-native) – for example migrating from a monolithic architecture to a serverless architecture.
Remain
Retain/revisit
Perhaps because their application transformation strategies assume that there is always some transformation to be done, Gartner and Microsoft do not have a remain/retain option. This can be seen as the “do nothing” approach but, as AWS highlights, it’s really a revisit as the do nothing is a holding state. Maybe the application will be deprecated soon – or was recently purchased/upgraded and so is not a priority for further investment. It is likely to be addressed by one of the other approaches at some point in future.
Retire
Retire
Sometimes, an application has outlived its usefulness – or just costs more to run than it delivers in value, and should be retired. Neither Gartner nor Microsoft recognise this within their 5Rs.
Whichever 5 or 6Rs approach you take, it can be a useful approach for categorising potential transformation opportunities and I’m often surprised exercise how it exposes services that are consuming resources, long after their usefulness has ended.
This content is 4 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
Backup, Archive, High Availbility, Disaster Recovery, Business Continuity. All related. Yet all different.
One of my colleagues was recently faced with needing to run “a DR [disaster recovery] workshop” for a client. My initial impression was:
What disasters are they planning for?
I’ll bet they are thinking about Coronavirus and working remotely. That’s not really DR.
Or are they really thinking about a backup strategy?
So I decided to turn some of my rambling thoughts into a blog post. Each of these topics could be a post in its own right – I’m just scraping the surface here…
Let’s start with backup (and recovery)
Backups (of data) are a fairly simple concept. Anything that would create a problem if it was lost should be backed up. For example, my digital photos are considered to not exist at all unless they are synchronised (or backed up) to at least two other places (some network-attached storage, and the cloud).
In a business context, we run backups in order to be able to recover (restore) our content (configuration or data) within a given window. We may have weekly full backups and daily incremental or differential backups (perhaps with more regular snapshots), then retain parent, grandparent and great-grandparent copies of the full backups (four weeks) and keep each of these as (lunar) monthly backups for a year. That’s just an example – each organisation will have its own backup/retention policies and those backups may be stored on or off-site, on tape or disk.
In summary, backups are about making sure we have an up to date copy of our important configuration information and data, so we can recover it if the primary copy is lost or damaged.
And for bonus content, some services we might consider in a modern infrastructure context include Azure Backup or AWS Backup.
Backups must be verified and periodically tested in order to have any use.
Archiving information
When I wrote about backups above, I mentioned keeping multiple copies covering various points in time. Whilst some may consider this adequate for archival, archival is the storage of data for long-term preservation of read-only access – for example, documents that must be stored for an extended period of time (for example 7, 10, 25, 99 years). Once that would have been paper documents, in boxes. Now it might be digital files (or database contents) on tape or disk (potentially cloud storage).
Archival might still use backup software and associated retention policies, but we’ll think carefully about the medium we store it on. For very long term physical storage we might need to consider the media formats (paper is bulky and transferred to microfiche, or old magnetic media degrades, so it’s moved to optical storage – but the hardware becomes obsolete, so it’s moved to another format). If storing on disk (on-premises or in the cloud), we can use slower (cheaper) disks and accept that restoration from the archive may take additional time.
In summary, archival is about long-term data storage, generally measured in many years and archives might be stored off-line, or near-line.
Technologies we might use for archival are similar to backups, but we could consider lower-cost storage – e.g. Azure Storage‘s Cool or Archive tiers or Amazon S3 Glacier.
Keeping systems highly available
High Availability (HA) is about making sure that our systems are available for as much time as possible – or certainly within a given service level agreement (SLA).
Traditionally, we used technologies like a redundant array of inexpensive devices (RAID) for disks or memory, error checking memory, or redundant power supplies. We might also have created server clusters or farms. All of these methods have the intention of removing single points of failure (SPOFs).
In the cloud, we leave a lot of the infrastructure considerations to the cloud service provider and we design for failure in other ways.
We assume that virtual machines will fail and create availability sets.
We plan to scale out across multiple hosts for applications that can take advantage of that architecture.
We store data in multiple regions.
We may even consider multiple clouds.
Again, the level of redundancy built into the app and its supporting infrastructure must be designed according to requirements – as defined by the SLA. There may be no point in providing an expensive four nines uptime for an application that’s used once a month by one person, who works normal office hours. But, then again, what if that application is business critical – like payroll? Again, refer to the SLA – and maybe think about business continuity too… more on that in a moment.
Some of my clients have tried to implement Windows Server clusters in Azure. I’ve yet to be convinced and still consider that it’s old-world thinking applied in a contemporary scenario. There are better ways to design a highly available file service in 2020.
In summary, high availability is about ensuring that an application or service is available within the requirements of the associated service level agreement.
Technologies might include some of the hardware considerations I listed earlier, but these days we’re probably thinking more about:
Remember to also consider other applications/systems upon which an application relies.
Also, quoting from some of Microsoft’s training materials:
“To achieve four 9’s (99.99%), you probably can’t rely on manual intervention to recover from failures. The application must be self-diagnosing and self-healing.
Beyond four 9’s, it is challenging to detect outages quickly enough to meet the SLA.
Think about the time window that your SLA is measured against. The smaller the window, the tighter the tolerances. It probably doesn’t make sense to define your SLA in terms of hourly or daily uptime.”
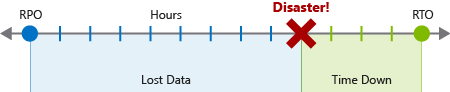
As the name suggests, Disaster Recovery (DR) is about recovering from a disaster, whatever that might be.
It could be physical damage to a piece of hardware (a switch, a server) that requires replacement or recovery from backup. It could be a whole server room or datacentre that’s been damaged or destroyed. It could be data loss as a result of malicious or accidental actions by an employee.
This is where DR plans come into play- firstly analysing the risks that might lead to disaster (including possible data loss and major downtime scenarios) and then looking at recovery objectives – the application’s recovery point objective (RPO) and recovery time objective (RTO).
Quoting Microsoft’s training materials again:
“Recovery Point Objective (RPO): The maximum duration of acceptable data loss. RPO is measured in units of time, not volume: “30 minutes of data”, “four hours of data”, and so on. RPO is about limiting and recovering from data loss, not data theft.
Recovery Time Objective (RTO): The maximum duration of acceptable downtime, where “downtime” needs to be defined by your specification. For example, if the acceptable downtime duration is eight hours in the event of a disaster, then your RTO is eight hours.”
For example, I may have a database that needs to be able to withstand no more than 15 minutes’ data loss and an associated SLA that dictates no more than 4 hours’ downtime in a given period. For that, my RPO is 15 minutes and the RTO is 4 hours. I need to make sure that I take snapshots (e.g. of transaction logs for replay) at least every 15 minutes and that my restoration process to get from offline to fully recovered takes no more than 4 hours (which will, of course, determine the technologies used).
Considerations when creating a DR plan might include:
What are the requirements for each application/service?
How are systems linked – what are the dependencies between applications/services?
How will you recover within the required RPO and RTO constraints?
How can replicated data be switched over?
Are there multiple environments (e.g. dev, test and production)?
How will you recover from logical errors in a database that might impact several generations of backup, or that may have spread through multiple data replicas?
What about cloud services – do you need to backup SaaS data (e.g. Office 365)? (Possibly not, if you’re happy with a retention-period based restoration from a “recycle bin” or similar but what if an administrator deletes some data?)
As can be seen, there are many factors here – more than I can go into in this blog post, but a disaster recovery strategy needs to consider backup/recovery, archive, availability (high or otherwise), technology and service (it may help to think about some of the ITIL service design processes).
In summary, disaster recovery is about having a plan to be able to recover from an event that results in downtime and data loss.
Technologies that might help include Azure Site Recovery. Applications can also be designed with data replication and recovery in mind, for example, using geo-replication capabilities in Azure Storage/Amazon S3, Azure SQL Server/Amazon RDS or using a globally-distributed database such as Azure Cosmos DB. And DR plans must be periodically tested.
Business continuity
Finally, Business Continuity (BC). This is something that many organisations will have had to contend with over the last few weeks and months.
BC is often confused with DR but they are different. Business continuity is about continuing to conduct business when something goes wrong. That may be how to carry on working whilst working on recovering from a disaster. Or it may be how to adapt processes to allow a workforce to continue functioning in compliance with social distancing regulations.
Again, BC needs a plan. But many of those plans will be reconsidered now – if your BC arrangements are that in the event of an office closure, people go to a hosted DR site with some spare equipment that will be made available within an agreed timescale, that might not help in the event of a global pandemic, when everyone else wants to use that facility. Instead, how will your workforce continue to work at home? Which systems are important?How will you provide secure remote access to those systems? (How will you serve customers whilst employees are also looking after children?) The list goes on.
Technology may help with BC, but technology alone will not provide a solution. The use of modern approaches to End User Computing will certainly make secure remote and mobile working a possibility (indeed, organisations that have taken a modern approach will probably already be familiar with those practices) but a lot of the issues will relate to people and process.
In summary, Business Continuity plans may be invoked if there is a disaster but they are about adapting business processes to maintain service in times of disruption.
Wrapping up
As I was writing this post, I thought about many tangents that I could go off and cover. I’m pretty sure the topic could be a book and this post scrapes the surface. Nevertheless, I hope my thoughts are useful and show that disaster recovery cannot be considered in isolation.
This content is 5 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
A couple of years ago, I wrote a post about a logical view of an End-User Computing (EUC) architecture (which provides a platform for Modern Workplace). It’s served me well and the model continues to be developed (although the changes are subtle so it’s not really worth writing a new post for the 2019 version).
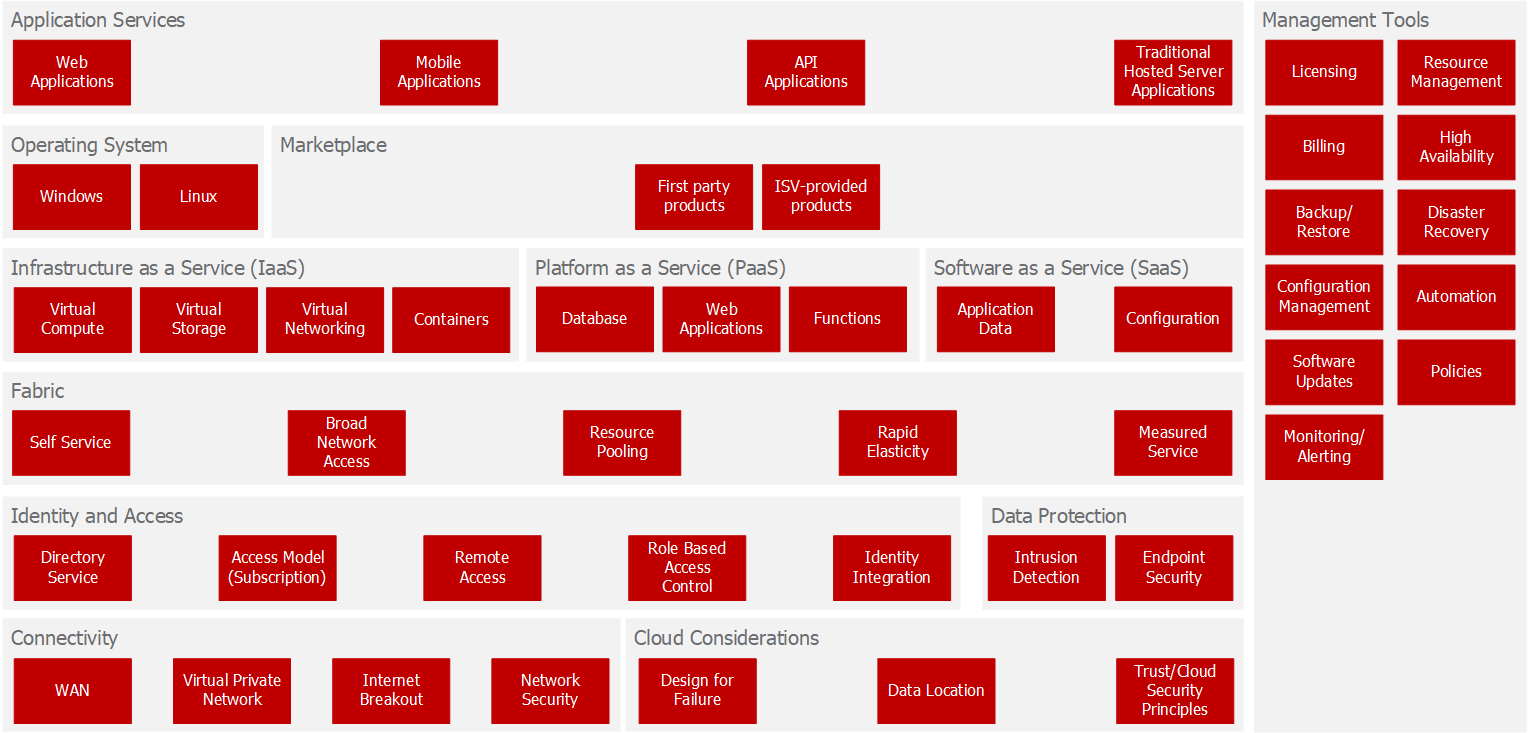
Building on the original EUC/Modern Workplace framework, I started to think what it might look like for datacentre services – and this is something I came up with last year that’s starting to take shape.
Just as for the EUC model, I’ve tried to step up a level from the technology – to get back to the logical building blocks of the solution so that I can apply them according to a specific client’s requirements. I know that it’s far from complete – just look at an Azure or AWS feature list and you can come up with many more classifications for cloud services – but I think it provides the basics and a starting point for a conversation:
Starting at the bottom left of the diagram, I’ll describe each of the main blocks in turn:
Whether hosted on-premises, co-located or making use of public cloud capabilities, Connectivity is a key consideration for datacentre services. This element of the solution includes the WAN connectivity between sites, site-to-site VPN connections to secure access to the datacentre, Internet breakout and network security at the endpoints – specifically the firewalls and other network security appliances in the datacentre.
Whilst many of the SBBs in the virtual datacentre services architecture are equally applicable for co-located or on-premises datacentres, there are some specific Cloud Considerations. Firstly, cloud solutions must be designed for failure – i.e. to design out any elements that may lead to non-availability of services (or at least to fail within agreed service levels). Depending on the organisation(s) consuming the services, there may also be considerations around data location. Finally, and most significantly, the cloud provider(s) must practice trustworthy computing and, ideally, will conform to the UK National Cyber Security Centre (NCSC)’s 14 cloud security principles (or equivalent).
Just as for the EUC/Modern Workplace architecture, Identity and Access is key to the provision of virtual datacentre services. A directory service is at the heart of the solution, combined with a model for limiting the scope of access to resources. Together with Role Based Access Control (RBAC), this allows for fine-grained access permissions to be defined. Some form of remote access is required – both to access services running in the datacentre and for management purposes. Meanwhile, identity integration is concerned with integrating the datacentre directory service with existing (on-premises) identity solutions and providing SSO for applications, both in the virtual datacentre and elsewhere in the cloud (i.e. SaaS applications).
Data Protection takes place throughout the solution – but key considerations include intrusion detection and endpoint security. Just as for end-user devices, endpoint security covers such aspects as firewalls, anti-virus/malware protection and encryption of data at rest.
In the centre of the diagram, the Fabric is based on the US National Institute of Standards and Technology (NIST)’s established definition of essential characteristics for cloud computing.
The NIST guidance referred to above also defines three service models for cloud computing: Infrastructure as a Service (IaaS); Platform as a Service (PaaS) and Software as a Service (SaaS).
In the case of IaaS, there are considerations around the choice of Operating System. Supported operating systems will depend on the cloud service provider.
Many cloud service providers will also provide one or more Marketplaces with both first and third-party (ISV) products ranging from firewalls and security appliances to pre-configured application servers.
Application Services are the real reason that the virtual datacentre services exist, and applications may be web, mobile or API-based. There may also be traditional hosted server applications – especially where IaaS is in use.
The whole stack is wrapped with a suite of Management Tools. These exist to ensure that the cloud services are effectively managed in line with expected practices and cover all of the operational tasks that would be expected for any datacentre including: licensing; resource management; billing; HA and disaster recovery/business continuity; backup and recovery; configuration management; software updates; automation; management policies and monitoring/alerting.
If you have feedback – for example, a glaring hole or suggestions for changes, please feel free to leave a comment below.
This content is 5 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
Even with a predominantly Microsoft-focused client base, there are situations where a multi-cloud solution is required and so, it makes sense for me to expand my knowledge to include Amazon’s cloud offerings. I may not have the detail and experience that I have with Microsoft Azure, but certainly enough to make an informed choice within my Architect role.
One of the first things I noticed is that, for Amazon, it’s all about the numbers. The AWS Summit had a lot of attendees – 12000+ were claimed, for more than 60 technical sessions supported by 98 sponsoring partners. Frankly, it felt to me that there were a few too many people there at times…
AWS is clearly growing – citing 41% growth comparing Q1 2019 with Q1 2018. And, whilst the comparisons with the industrial revolution and the LSE research that shows 95% of today’s startups would find traditional IT models limiting today were all good and valid, the keynote soon switched to focus on AWS claims of “more”. More services. More depth. More breadth.
I’m tired of rhetoric from cloud providers trying to demonstrate one-upmanship. Real customers don’t care about number of services: they want to know how to save money, increase agility whilst remaining secure and compliant. They can do that on AWS or Azure… select best fit…
There were some good customer slots in the keynote: Sainsbury’s Group CIO Phil Jordan and Group Digital Officer Clodagh Moriaty spoke about improving online experiences, integrating brands such as Nectar and Sainsbury’s, and using machine learning to re-plan retail space and to plan online deliveries. Ministry of Justice CDIO Tom Read talked about how the MOJ is moving to a microservice-based application architecture.
After the keynote, I immersed myself in technical sessions. In fact, I avoided the vendor booths completely because the room was absolutely packed when I tried to get near. My afternoon consisted of:
Driving digital transformation using artificial intelligence by Steven Bryen (@Steven_Bryen) and Bjoern Reinke.
AWS networking fundamentals by Perry Wald and Tom Adamski.
Creating resilience through destruction by Adrian Hornsby (@adhorn).
How to build an Alexa Skill in 30 minutes by Andrew Muttoni (@muttonia).
All of these were great technical sessions – and probably too much for a single blog post but, here goes anyway…
Driving digital transformation using artificial intelligence
Amazon thinks that driving better customer experience requires Artificial Intelligence (AI), specifically Machine Learning (ML). Using an old picture of London Underground workers sorting through used tickets in the 1950s to identify the most popular journeys, Steven Bryen suggested that more data leads to better analytics and better outcomes that can be applied in more ways (in a cyclical manner).
Data (specifically the ability to capture and store it at scale).
GPUs and acceleration.
Cloud computing.
Citing research from PwC [which I can’t find on the Internet], AWS claim that world GDP was $80Tn in 2018 and is expected to be $112Tn in 2030 ($15.7Tn of which can be attributed to AI).
Data science, artificial intelligence, machine learning and deep learning can be thought of as a series of concentric rings.
Machine learning can be supervised learning (betting better at finding targets); unsupervised (assume nothing and question everything); or reinforcement learning (rewarding high performing behaviour).
Amazon claims extensive AI experience through its own ML experience:
Recommendations Engine
Prime Air
Alexa
Go (checkoutless stores)
Robotic warehouses – taking trolleys to packer to scan and pack (using an IoT wristband to make sure robots avoid maintenance engineers).
Every day Amazon applies new AI/ML-based improvements to its business, at a global scale through AWS.
Challenges for organisations are that:
ML is rare
plus: Building and scaling ML technology is hard
plus: Deploying and operating models in production is time-consuming and expensive
equals: a lack of cost-effective easy-to-use and scalable ML services
Most time is spent getting data ready to get intelligence from it. Customers need a complete end-to-end ML stack and AWS provides that with edge technologies such as Greengrass for offline inference and modelling in SageMaker. The AWS view is that ML prediction becomes a RESTful API call.
With the scene set, Steven Bryen handed over to Bjoern Reinke, Drax Retail’s Director of Smart Metering.
Drax has converted former coal-fired power stations to use biomass: capturing carbon into biomass pellets, which are burned to create steam that drives turbines – representing 15% of the UK’s renewable energy.
Drax uses a systems thinking approach with systems of record, intelligence and engagement
System of intelligence need:
Trusted data.
Insight everywhere.
Enterprise automation.
Customers expect tailoring: efficiency; security; safety; and competitive advantage.
Systems of intelligence can be applied to team leaders, front line agents (so they already know that customer has just been online looking for a new tariff), leaders (for reliable data sources), and assistant-enabled recommendations (which are no longer futuristic).
Fragmented/conflicting data is pumped into a data lake from where ETL and data warehousing technologies are used for reporting and visualisation. But Drax also pull from the data lake to run analytics for data science (using Inawisdom technology).
The data science applications can monitor usage and see base load, holidays, etc. Then, they can look for anomalies – a deviation from an established time series. This might help to detect changes in tenants, etc. and the information can be surfaced to operations teams.
After hearing how AWS can be used to drive insight into customer activities, the next session was back to pure tech. Not just tech but infrastructure (all be it as a service). The following notes cover off some AWS IaaS concepts and fundamentals.
Customers deploy into virtual private cloud (VPC) environments within AWS:
For demonstration purposes, a private address range (CIDR) was used – 172.31.0.0/16 (a private IP range from RFC 1918). Importantly, AWS ranges should be selected to avoid potential conflicts with on-premises infrastructure. Amazon recommends using /16 (65536 addresses) but network teams may suggest something smaller.
AWS is dual-stack (IPv4 and IPv6) so even if an IPv6 CIDR is used, infrastructure will have both IPv4 and IPv6 addresses.
Each VPC should be broken into availability zones (AZs), which are risk domains on different power grids/flood profiles and a subnet placed in each (e.g. 172.31.0.0/24, 172.31.1.0/24, 172.31.2.0/24).
Each VPC has a default routing table but an administrator can create and assign different routing tables to different subnets.
To connect to the Internet you will need a connection, a route and a public address:
Create a public subnet (one with public and private IP addresses).
Then, create an Internet Gateway (IGW).
Finally, Create a route so that the default gateway is the IGW (172.31.0.0/16 local and 0.0.0.0/0 igw_id).
Alternatively, create a private subnet and use a NAT gateway for outbound only traffic and direct responses (172.31.0.0/16 local and 0.0.0.0/0 nat_gw_id).
Moving on to network security:
Network Security Groups (NSGs) provide a stateful distributed firewall so a request from one direction automatically sets up permissions for a response from the other (avoiding the need to set up separate rules for inbound and outbound traffic).
Using an example VPC with 4 web servers and 3 back end servers:
Group into 2 security groups
Allow web traffic from anywhere to web servers (port 80 and source 0.0.0.0/0)
Only allow web servers to talk to back end servers (port 2345 and source security group ID)
Network Access Control Lists (NACLs) are stateless – they are just lists and need to be explicit to allow both directions.
Flow logs work at instance, subnet or VPC level and write output to S3 buckets or CloudWatch logs. They can be used for:
Visibility
Troubleshooting
Analysing traffic flow (no payload, just metadata)
Network interface
Source IP and port
Destination IP and port
Bytes
Condition (accept/reject)
DNS in a VPC is switched on by default for resolution and assigning hostnames (rather than just using IP addresses).
AWS also has the Route 53 service for customers who would like to manage their own DNS.
Finally, connectivity options include:
Peering for private communication between VPCs
Peering is 1:1 and can be in different regions but the CIDR must not overlap
Each VPC owner can send a request which is accepted by the owner on the other side. Then, update the routing tables on the other side.
Peering can get complex if there are many VPCs. There is also a limit of 125 peerings so a Transit Gateway can be used to act as a central point but there are some limitations around regions.
Each Transit Gateway can support up to 5000 connections.
AWS can be connected to on-premises infrastructure using a VPN or with AWS Direct Connect
A VPN is established with a customer gateway and a virtual private gateway is created on the VPC side of the connection.
Each connection has 2 tunnels (2 endpoints in different AZs).
Update the routing table to define how to reach on-premises networks.
Direct Connect
AWS services on public address space are outside the VPC.
Direct Connect locations have a customer or partner cage and an AWS cage.
Create a private virtual interface (VLAN) and a public virtual interface (VLAN) for access to VPC and to other AWS services.
A Direct Connect Gateway is used to connect to each VPC
Before Transit Gateway customers needed a VPN per VPC.
Now they can consolidate on-premises connectivity
For Direct Connect it’s possible to have a single tunnel with a Transit Gateway between the customer gateway and AWS.
Route 53 Resolver service can be used for DNS forwarding on-premises to AWS and vice versa.
VPC Sharing provides separation of resources with:
An Owner account to set up infrastructure/networking.
Subnets shared with other AWS accounts so they can deploy into the subnet.
Interface endpoints make an API look as if it’s part of an organisation’s VPC.
They override the public domain name for service.
Using a private link can only expose a specific service port and control the direction of communications and no longer care about IP addresses.
Amazon Global Accelerator brings traffic onto the AWS backbone close to end users and then uses that backbone to provide access to services.
Creating resilience through destruction
One of the most interesting sessions I saw at the AWS Summit was Adrian Horn’s session that talked about deliberately breaking things to create resilience – which is effectively the infrastructure version of test-driven development (TDD), I guess…
Actually, Adrian made the point that it’s not so much the issues that bringing things down causes as the complexity of bringing them back up.
“Failures are a given and everything will eventually fail over time”
Werner Vogels, CTO, Amazon.com
We may break a system into microservices to scale but we also need to think about resilience: the ability for a system to handle and eventually recover from unexpected conditions.
This needs to consider a stack that includes:
People
Application
Network and Data
Infrastructure
And building confidence through testing only takes us so far. Adrian referred to another presentation, by Jesse Robbins, where he talks about creating resilience through destruction.
Firefighters train to build intuition – so they know what to do in the event of a real emergency. In IT, we have the concept of chaos engineering – deliberately injecting failures into an environment:
Start small and build confidence:
Application level
Host failure
Resource attacks (CPU, latency…)
Network attacks (dependencies, latency…)
Region attack
Human attack (remove a key resource)
Then, build resilient systems:
Steady state
Hypothesis
Design and run an experiment
Verify and learn
Fix
(maybe go back to experiment or to start)
And use bulkheads to isolate parts of the system (as in shipping).
Think about:
Software:
Certificate Expiry
Memory leaks
Licences
Versioning
Infrastructure:
Redundancy (multi-AZ)
Use of managed services
Bulkheads
Infrastructure as code
Application:
Timeouts
Retries with back-offs (not infinite retries)
Circuit breakers
Load shedding
Exception handing
Operations:
Monitoring and observability
Incident response
Measure, measure, measure
You build it, your run it
AWS’ Well Architected framework has been developed to help cloud architects build secure, high-performing, resilient, and efficient infrastructure for their applications, based on some of these principles.
Adrian then moved on to consider what a steady state looks like:
Normal behaviour of system
Business metric (e.g. pulse of Netflix – multiple clicks on play button if not working)
Amazon extra 100ms load time led to 1% drop in sales (Greg Linden)
Google extra 500ms of load time led to 20% fewer searches (Marissa Mayer)
Yahoo extra 400ms of load time caused 5-9% increase in back clicks (Nicole Sullivan)
He suggests asking questions about “what if?” and following some rules of thumb:
Start very small
As close as possible to production
Minimise the blast radius
Have an emergency stop
Be careful with state that can’t be rolled back (corrupt or incorrect data)
Use canary deployment with A-B testing via DNS or similar for chaos experiment (1%) or normal (99%).
Adrian then went on to demonstrate his approach to chaos engineering, including:
Fault injection
queries for Amazon Aurora (can revert immediately)
Sit between components and add “toxics” to
test impact of issues
Kube-Money
project (for Kubernetes)
Pumba (for
Docker)
Thundra (for
Lambda)
Use post mortems for correction of errors – the 5 whys. Also, understand that there is no isolated “cause” of an accident.
My notes don’t do Adrian’s talk justice – there’s so much more that I could pick up from re-watching his presentation. Adrian tweeted a link to his slides and code – if you’d like to know more, check them out:
Spoiler: I didn’t have a working Alexa skill at the end of my 30 minutes… nevertheless, here’s some info to get you started!
Amazon’s view is that technology tries to constrain us. Things got better with mobile and voice is the next step forward. With voice, we can express ourselves without having to understand a user interface [except we do, because we have to know how to issue commands in a format that’s understood – that’s the voice UI!].
I get the point being made – to add an item to a to-do list involves several steps:
Find phone
Unlock phone
Find app
Add item
etc.
Or, you could just say (for example) “Alexa, ask Ocado to add tuna to my trolley”.
Alexa is a service in the AWS cloud that understands request and acts upon them. There are two components:
Alexa voice service – how a device manufacturer adds Alexa to its products.
Alexa Skills Kit – to create skills that make something happen (and there are currently more than 80,000 skills available).
An Alexa-enabled device only needs to know to wake up, then stream some “mumbo jumbo” to the cloud, at which point:
Automatic speech recognition with translate text to speech
Natural language understanding will infer intent (not just text, but understanding…)
Looking back, the technical sessions made my visit to the AWS Summit worthwhile but overall, I was a little disappointed, as this tweet suggests:
End of day verdict on #AWSSummit: disappointing keynote (see https://t.co/BOFiQacH5f); good breakout sessions (at least the ones I went to); awful conference app (feedback is painfully slow); OK catering; too many people (so I skipped the expo). Learned lots but hoped for more… pic.twitter.com/QtUcaKqoAS
Would I recommend the AWS Summit to others? Maybe. Would I watch the keynote from home? No. Would I try to watch some more technical sessions? Absolutely, if they were of the quality I saw on the day. Would I bother to go to ExCeL with 12000 other delegates herded like cattle? Probably not…
This content is 5 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
One of the most valuable personal development activities in my early career was a trip to the Microsoft TechEd conference in Amsterdam. I learned a lot – not just technically but about making the most of events to gather information, make new industry contacts, and generally top up my knowledge. Indeed, even as a relatively junior consultant, I found that dipping into multiple topics for an hour or so gave me a really good grounding to discover more (or just enough to know something about the topic) – far more so than an instructor-led training course.
Over the years, I attended further “TechEd”s in Amsterdam, Barcelona and Berlin. I fought off the “oh Mark’s on another jolly” comments by sharing information – incidentally, conference attendance is no “jolly” – there may be drinks and even parties but those are after long days of serious mental cramming, often on top of broken sleep in a cheap hotel miles from the conference centre.
Microsoft TechEd is no more. Over the years, as the budgets were cut, the standard of the conference dropped and in the UK we had a local event called Future Decoded. I attended several of these – and it was at Future Decoded that I discovered risual – where I’ve been working for almost four years now.
Now, Future Decoded has also fallen by the wayside and Microsoft has focused on taking it’s principal technical conference – Microsoft Ignite – on tour, delivering global content locally.
So, a few weeks ago, I found myself at the ExCeL conference centre in London’s Docklands, looking forward to a couple of days at “Microsoft Ignite | The Tour: London”.
Conference format
Just like TechEd, and at Future Decoded (in the days before I had to use my time between keynotes on stand duty!), the event was broken up into tracks with sessions lasting around an hour. Because that was an hour of content (and Microsoft event talks are often scheduled as an hour, plus 15 minutes Q&A), it was pretty intense, and opportunities to ask questions were generally limited to trying to grab the speaker after their talk, or at the “Ask the Experts” stands in the main hall.
One difference to Microsoft conferences I’ve previously attended was the lack of “level 400” sessions: every session I saw was level 100-300 (mostly 200/300). That’s fine – that’s the level of content I would expect but there may be some who are looking for more detail. If it’s detail you’re after then Ignite doesn’t seem to be the place.
Also, I noticed that Day 2 had fewer delegates and lacked some of the “hype” from Day 1: whereas the Day 1 welcome talk was over-subscribed, the Day 2 equivalent was almost empty and light on content (not even giving airtime to the conference sponsors). Nevertheless, it was easy to get around the venue (apart from a couple of pinch points).
Personal highlights
I managed to cover 11 topics over two days (plus a fair amount of networking). The track format of the event was intended to let a delegate follow a complete learning path but, as someone who’s a generalist (that’s what Architects have to be), I spread myself around to cover:
Dealing with a massive onset of data ingestion (Jeramiah Dooley/@jdooley_clt).
Enterprise network connectivity in a cloud-first world (Paul Collinge/@pcollingemsft).
Building a world without passwords.
Discovering Azure Tooling and Utilities (Simona Cotin/@simona_cotin).
Selecting the right data storage strategy for your cloud application (Jeramiah Dooley/@jdooley_clt).
Planning and implementing hybrid network connectivity (Thomas Maurer/@ThomasMaurer).
Transform device management with Windows Autopilot, Intune and OneDrive (Michael Niehaus/@mniehaus and Mizanur Rahman).
Maintaining your hybrid environment (Niel Peterson/@nepeters).
Windows Server 2019 Deep Dive (Jeff Woolsey/@wsv_guy).
Consolidating infrastructure with the Azure Kubernetes Service (Erik St Martin/@erikstmartin).
In the past, I’d have written a blog post for each topic. I was going to say that I simply don’t have the time to do that these days but by the time I’d finished writing this post, I thought maybe I could have split it up a bit more! Regardless, here are some snippets of information from my time at Microsoft Ignite | The Tour: London. There’s more information in the slide decks – which are available for download, along with the content for the many sessions I didn’t attend.
Data ingestion
Ingesting data can be broken into:
Real-time ingestion.
Real-time analysis (see trends as they happen – and make changes to create a competitive differentiator).
Producing actions as patterns emerge.
Automating reactions in external services.
Making data consumable (in whatever form people need to use it).
Cloud traffic is increasing whilst traffic that remains internal to the corporate network is in decline. Traditional management approaches are no longer fit for purpose.
Office applications use multiple persistent connections – this causes challenges for proxy servers which generally degrade the Office 365 user experience. Remediation is possible, with:
Let Microsoft route traffic (data is in a region, not a place). Use DNS resolution to egress connections close to the user (a list of all Microsoft peering locations is available). Optimise the route length and avoid hairpins.
Assess network security using application-level security, reducing IP ranges and ports and evaluating the service to see if some activities can be performed in Office 365, rather than at the network edge (e.g. DLP, AV scanning).
For Azure:
Azure ExpressRoute is a connection to the edge of the Microsoft global backbone (not to a datacentre). It offers 2 lines for resilience and two peering types at the gateway – private and public (Microsoft) peering.
Azure Virtual WAN can be used to build a hub for a region and to connect sites.
Replace branch office routers with software-defined (SDWAN) devices and break out where appropriate.
Planning
and implementing hybrid network connectivity
Moving to the cloud allows for fast deployment but planning is just as important as it ever was. Meanwhile, startups can be cloud-only but most established organisations have some legacy and need to keep some workloads on-premises, with secure and reliable hybrid communication.
Considerations include:
Extension of the internal protected network:
Should workloads in Azure only be accessible from the Internal network?
Are Azure-hosted workloads restricted from accessing the Internet?
Should Azure have a single entry and egress point?
Can the connection traverse the public Internet (compliance/regulation)?
IP addressing:
Existing addresses on-premises; public IP addresses.
Namespaces and name resolution.
Multiple regions:
Where are the users (multiple on-premises sites); where are the workloads (multiple Azure regions); how will connectivity work (should each site have its own connectivity)?
Encrypted traffic over the public Internet to the GatewaySubnet in Azure, which hosts VPN Gateway VMs.
99.9% SLA on the Gateway in Azure (not the connection).
Don’t deploy production workloads on the GatewaySubnet; /26, /27 or /28 subnets recommended; don’t apply NSGs to the GatewaySubnet – i.e. let Azure manage it.
Dedicated connections (Azure ExpressRoute): private connection at up to 10Gbps to Azure with:
Private peering (to access Azure).
Microsoft peering (for Office 365, Dynamics 365 and Azure public IPs).
99.9% SLA on the entire connection.
Other connectivity services:
Azure ExpressRoute Direct: a 100Gbps direct connection to Azure.
Azure ExpressRoute Global Reach: using the Microsoft network to connect multiple local on-premises locations.
Azure Virtual WAN: branch to branch and branch to Azure connectivity with software-defined networks.
Azure File Sync offers tiered storage for Windows Server with Azure file storage and rapid disaster recovery. Can be thought of as “OneDrive for servers”.
Modern Device Management (Autopilot, Intune and OneDrive)
The old way of managing PC builds:
Build an image with customisations and drivers
Deploy to a new computer, overwriting what was on it
Expensive – and the device has a perfectly good OS – time-consuming
Instead, how about:
Unbox PC
Transform with minimal user interaction
Device is ready for productive use
The transformation is:
Take OEM-optimised Windows 10:
Windows 10 Pro and drivers.
Clean OS.
Plus software, settings, updates, features, user data (with OneDrive for Business).
Ready for productive use.
The goal is to reduce the overall cost of deploying devices. Ship to a user with half a page of instructions…
Autopilot deployment is cloud driven and will eventually be centralised through Intune:
Register device:
From OEM or Channel (manufacturer, model and serial number).
Automatically (existing Intune-managed devices).
Manually using a PowerShell script to generate a CSV file with serial number and hardware hash, which is then uploaded to the Intune portal.
Assign Autopilot profile:
Use Azure AD Groups to assign/target.
The profile includes settings such as deployment mode, BitLocker encryption, device naming, out of box experience (OOBE).
An Azure AD device object is created for each imported Autopilot device.
Boot to OOBE, choose language, locale, keyboard and provide credentials.
The device is joined to Azure AD, enrolled to Intune and policies are applied.
User signs on and user-assigned items from Intune policy are applied.
Once the desktop loads, everything is present, including file links in OneDrive) – time depends on the software being pushed.
Self-deploying (e.g. kiosk, digital signage):
No credentials required; device authenticates with Azure AD using TPM 2.0.
User-driven with hybrid Azure AD join:
Requires Offline Domain Join Connector to create AD DS computer account.
Device connected to the corporate network (in order to access AD DS), registered with Autopilot, then as before.
Sign on to Azure AD and then to AD DS during deployment. If they use the same UPN then it makes things simple for users!
Autopilot for existing devices (Windows 7 to 10 upgrades):
Backup data in advance (e.g. with OneDrive)
Deploy generic Windows 10.
Run Autopilot user-driven mode (can’t harvest hardware hashes in Windows 7 so use a JSON config file in the image – the offline equivalent of a profile. Intune will ignore unknown device and Autopilot will use the file instead; after deployment of Windows 10, Intune will notice a PC in the group and apply the profile so it will work if the PC is reset in future).
Autopilot roadmap (1903) includes:
“White glove” pre-provisioning for end users: QR code to track, print welcome letter and shipping label!
Enrolment status page (ESP) improvements.
Cortana voiceover disabled on OOBE.
Self-updating Autopilot (update Autopilot without waiting to update Windows).
Common requirements in an IaaS environment include wanting to use a policy-based configuration with a single management and monitoring solution and auto-remediation.
Azure Automation allows configuration and inventory; monitoring and insights; and response and automation. The Azure Portal provides a single pane of glass for hybrid management (Windows or Linux; any cloud or on-premises).
For configuration and state management, use Azure Automation State Configuration (built on PowerShell Desired State Configuration).
Inventory can be managed with Log Analytics extensions for Windows or Linux. An Azure Monitoring Agent is available for on-premises or other clouds. Inventory is not instant though – can take 3-10 minutes for Log Analytics to ingest the data. Changes can be visualised (for state tracking purposes) in the Azure Portal.
Azure Monitor and Log Analytics can be used for data-driven insights, unified monitoring and workflow integration.
Responding to alerts can be achieved with Azure Automation Runbooks, which store scripts in Azure and run them in Azure. Scripts can use PowerShell or Python so support both Windows and Linux). A webhook can be triggered with and HTTP POST request. A Hybrid runbook worker can be used to run on-premises or in another cloud.
It’s possible to use the Azure VM agent to run a command on a VM from Azure portal without logging in!
Windows Server 2019
Windows Server strategy starts with Azure. Windows Server 2019 is focused on:
Hybrid:
Backup/connect/replicate VMs.
Storage Migration Service to migrate unstructured data into Azure IaaS or another on-premises location (from 2003+ to 2016/19).
Inventory (interrogate storage, network security, SMB shares and data).
Transfer (pairings of source and destination), including ACLs, users and groups. Details are logged in a CSV file.
Cutover (make the new server look like the old one – same name and IP address). Validate before cutover – ensure everything will be OK. Read-only process (except change of name and IP at the end for the old server).
Azure File Sync: centralise file storage in Azure and transform existing file servers into hot caches of data.
Azure Network Adapter to connect servers directly to Azure networks (see above).
Hyper-converged infrastructure (HCI):
The server market is still growing and is increasingly SSD-based.
Traditional rack looked like SAN, storage fabric, hypervisors, appliances (e.g. load balancer) and top of rack Ethernet switches.
Now we use standard x86 servers with local drives and software-defined everything. Manage with Admin Center in Windows Server (see below).
Windows Server now has support for persistent memory: DIMM-based; still there after a power-cycle.
Security: shielded VMs for Linux (VM as a black box, even for an administrator); integrated Windows Defender ATP; Exploit Guard; System Guard Runtime.
Application innovation: semi-annual updates are designed for containers. Windows Server 2019 is the latest LTSC channel so it has the 1709/1803 additions:
Enable developers and IT Pros to create cloud-native apps and modernise traditional apps using containers and micro services.
Linux containers on Windows host.
Service Fabric and Kubernetes for container orchestration.
Windows subsystem for Linux.
Optimised images for server core and nano server.
Windows Admin Center is core to the future of Windows Server management and, because it’s based on remote management, servers can be core or full installations – even containers (logs and console). Download from http://aka.ms/WACDownload
50MB download, no need for a server. Runs in a browser and is included in Windows/Windows Server licence
Runs on a layer of PowerShell. Use the >_ icon to see the raw PowerShell used by Admin Center (copy and paste to use elsewhere).
Extensible platform.
What’s next?
More cloud integration
Update cadence is:
Insider builds every 2 weeks.
Semi-annual channel every 6 months (specifically for containers):
Azure Container Instances (ACI): containers on demand (Linux or Windows) with no need to provision VMs or clusters; per-second billing; integration with other Azure services; a public IP; persistent storage.
Azure App Service for Linux: a fully-managed PaaS for containers including workflows and advanced features for web applications.
So, there you have it. An extremely long blog post with some highlights from my attendance at Microsoft Ignite | The Tour: London. It’s taken a while to write up so I hope the notes are useful to someone else!
Fantastic couple of days at #MSIgniteTheTour (although quieter/smaller than I expected). Thanks to all the speakers – it’s been great to dip into such a wide variety of topics. Now, back to the day job (and normal tweeting levels!) pic.twitter.com/NtTDXOG22h
This content is 6 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
I recently heard a Consultant from another Microsoft partner talking about storing “IL3” information in Azure. That rang alarm bells with me, because Impact Levels (ILs) haven’t been a “thing” for UK Government data since April 2014. For the record, here’s the official guidance on the UK Government data security classifications and this video explains why the system was changed:
Meanwhile, this one is a good example of what it means in practice:
So, what does that mean for storing data in Azure, Dynamics 365 and Office 365? Basically, information classified OFFICIAL can be stored in the Microsoft Cloud – for more information, refer to the Microsoft Trust Center. And, because OFFICIAL-SENSITIVE is not another classification (it’s merely highlighting information where additional care may be needed), that’s fine too.
I’ve worked with many UK Government organisations (local/regional, and central) and most are looking to the cloud as a means to reduce costs and improve services. The fact that more than 90% of public data is classified OFFICIAL (indeed, that’s the default for anything in Government) is no reason to avoid using the cloud.
This content is 7 years old. I don't routinely update old blog posts as they are only intended to represent a view at a particular point in time. Please be warned that the information here may be out of date.
Just over a week ago, risual held its bi-annual summit at the risual HQ in Stafford – the whole company back in the office for a day of learning with a new format: a mini-conference called risual:NXT.
I was given the task of running the technical track – with 6 speakers presenting on a variety of topics covering all of our technical practices: Cloud Infrastructure; Dynamics; Data Platform; Unified Intelligent Communications and Messaging; Business Productivity; and DevOps – but I was also privileged to be asked to present a keynote session on technology trends. Unfortunately, my 35-40 minutes of content had to be squeezed into 22 minutes… so this blog post summarises some of the points I wanted to get across but really didn’t have the time.
Organisations need to transform their cloud operations because that’s where the benefits are – embrace the productivity tools in Office 365 (no longer just cloud versions of Exchange/Lync/SharePoint but a full collaboration stack) and look to build new solutions around advanced workloads in Azure. Microsoft is way ahead in the PaaS space – machine learning (ML), advanced analytics, the Internet of Things (IoT) – there are so many scenarios for exploiting cloud services that simply wouldn’t be possible on-premises without massive investment.
And for those who still think they can compete with the scale that Microsoft (Amazon and Google) operate at, this video might provide some food for thought…
(and for a similar video from a security perspective…)
2. Data: the fuel of the future
I hate referring to data as “the new oil”. Oil is a finite resource. Data is anything but finite! It is a fuel though…
Data is what provides an economic advantage – there are businesses without data and those with. Data is the business currency of the future. Think about it: Facebook and Google are entirely based on data that’s freely given up by users (remember, if you’re not paying for a service – you are the service). Amazon wouldn’t be where it is without data.
So, thinking about what we do with that data: the 1st wave of the Internet was about connecting computers, 2nd was about people, the 3rd is devices.
Despite what you might read, IoT is not about connected kettles/fridges. It’s not even really about home automation with smart lightbulbs, thermostats and door locks. It’s about gathering information from billions of sensors out there. Then, we take that data and use it to make intelligent decisions and apply them in the real world. Artificial intelligence and machine learning feed on data – they are ying and yang to each other. We use data to train algorithms, then we use the algorithms to process more data.
The Microsoft Data Platform is about analytics and data driving a new wave of insights and opening up possibilities for new ways of working.
James Watt’s 18th Century steam engine led to an industrial revolution. The intelligent cloud is today’s version – moving us to the intelligence revolution.
3 Blockchain
Bitcoin is just one implementation of something known as the Blockchain. In this case as a digital currency.
But Blockchain is not just for monetary transactions – it’s more than that. It can be used for anything transactional. Blockchain is about a distributed ledger. Effectively, it allows parties to trust one another without knowing each other. The ledger is a record of every transaction, signed and tamper-proof.
The magic about Blockchain is that as the chain gets longer so does the entropy and the encryption level – effectively, the more the chain is used, the more secure it gets. That means infinite integrity.
Blockchain is seen as strategic by Microsoft and by the UK government and it’s early days but we will see where people want to talk about integrity and data resilience with integrity. Databases – anything transactional – can be signed with blockchain.
(BTW, Bletchley is a town in Buckinghamshire that’s now absorbed into Milton Keynes. Bletchley Park was the primary location of the UK Government’s wartime code-cracking efforts that are said to have shortened WW2 by around 2 years. Not a bad name for a cryptographic technology, hey?)
4 Into the third dimension
So we’ve had the ability to “print” in 3 dimensions for a while but now 3D is going further.Now we’re taking physical worlds into the virtual world and augmenting with information.
To make use of this we need to be able to scan and render 3D images, then move them into a virtual world. 3D is built into next Windows 10 release (the Fall Creators update, due on 17 October 2017). This will bring Paint 3D, a 3D Gallery, View 3D for our phones – so we can scan any object and import to a virtual world. With the adoption rates of new Windows 10 releases then that puts 3D on a market of millions of PCs.
This Christmas will see lots of consumer headsets in the market. Mixed reality will really take off after that. Microsoft is way ahead in the plumbing – all whilst we didn’t notice. They held their Hololens product back to be big in business (so that it wasn’t a solution without a problem). Now it can be applied to field worker scenarios, visualising things before they are built.
To give an example, recently, I had a builder quote for a loft extension at home. He described how the stairs will work and sketched a room layout – but what if I could have visualised it in a headset? Then imagine picking the paint, sofas, furniture, wallpaper, etc.
The video below shows how Ford and Microsoft have worked together to use mixed reality to shorten and improve product development:
5 The new dawn of artificial intelligence
All of the legends of AI are set by sci-fi (Metropolis, 2001 AD, Terminator). But AI is not about killing us all! Humans vs. machines? Deep Blue beating people at Chess, Jeopardy, then Google taking on Go. Heading into the economy and displacing jobs. Automation of business process/economic activity. Mass unemployment?
Let’s take a more optimistic view! It’s not about sentient/thinking machines or giving human rights to machines. That stuff is interesting but we don’t know where consciousness comes from!
AI is a toolbox of high-value tools and techniques. We can apply these to problems and appreciate the fundamental shift from programming machines to machines that learn.
Ai is not about programming logical steps – we can’t do that when we’re recognising images, speech, etc. Instead, our inspiration is biology, neural networks, etc. – using maths to train complex layers of neural networks led to deep learning.
Image recognition was “magic” a few years ago but now it’s part of everyday life. Nvidia’s shares are growing massively due to GPU requirements for deep learning and autonomous vehicles. And Microsoft is democratising AI (in its own applications – with an intelligent cloud, intelligent agents and bots).
So, about those bots…
A bot is a web app and a conversational user interface. We use them because natural language processing (NLP) and AI are here today. And because messaging apps rule the world. With bots, we can use Human language as a new user interface; bots are the new apps – our digital assistants.
We can employ bots in several scenarios today – including customer service and productivity – and this video is just one example, with Microsoft Cortana built into a consumer product:
The device is similar to Amazon’s popular Echo smart speaker and a skills kit is used to teach Cortana about an app; Ask “skillname to do something”. The beauty of Cortana is that it’s cross-platform so the skill can show up wherever Cortana does. More recently, Amazon and Microsoft have announced Cortana-Alexa integration (meanwhile Siri continues to frustrate…)
AI is about augmentation, not replacement. It’s true that bots may replace humans for many jobs – but new jobs will emerge. And it’s already here. It’s mainstream. We use recommendations for playlists, music, etc. We’re recognising people, emotions, etc. in images. We already use AI every day…
6 From silicon to cells
Every cell has a “programme” – DNA. And researchers have found that they can write code in DNA and control proteins/chemical processes. They can compile code to DNA and execute, creating molecular circuits. Literally programming biology.
The benefits of DNA are that it’s very dense and it lasts for thousands of years so can always be read. And we’re just storing 0s and 1s – that’s much simpler than what DNA stores in nature.
With massive data storage… the next step is faster computing – that’s where Quantum computing comes in.
I’m a geek and this one is tough to understand… so here’s another video:
https://youtu.be/doNNClTTYwE
Quantum computing is starting to gain momentum. Dominated by maths (quantum mechanics), it requires thinking in equations, not translating into physical things in your head. It has concepts like superposition (multiple states at the same time) and entanglement. Instead of gates being turned on/off it’s about controlling particles with nanotechnology.
A classical 2 bit on-off takes 2 clock cycles. One quantum bit (a Qubit) has multiple states at the same time. It can be used to solve difficult problems (the RSA 2048 challenge problem would take a billion years on a supercomputer but just 100 seconds on a 250-bit quantum computer). This can be applied to encryption and security, health and pharma, energy, biotech, environment, materials and engineering, AI and ML.
There’s a race for quantum computing hardware taking place and China sees this as a massively strategic direction. Meanwhile, the UK is already an academic centre of excellence – now looking to bring quantum computing to market. We’ll have usable devices in 2-3 years (where “usable” means that they won’t be cracking encryption, but will have initial applications in chemistry and biology).
Amazon, Google and Microsoft each invest over $12bn p.a. on R&D. As demonstrated in the video above, their datacentres are not something that many organisations can afford to build but they will drive down the cost of computing. That drives down the cost for the rest of us to rent cloud services, which means more data, more AI – and the cycle continues.
I’ve shared 7 “technology bets” (and there are others, like the use of Graphene) that I haven’t covered – my list is very much influenced by my work with Microsoft technologies and services. We can’t always predict the future but all of these are real… the only bet is how big they are. Some are mainstream, some are up and coming – and some will literally change the world.
Credit: Thanks to Rob Fraser at Microsoft for the initial inspiration – and to Alun Rogers (@AlunRogers) for helping place some of these themes into context.